FireEye’s Flare-On Challenge is an annual, purely reverse engineering-focused capture the flag event. This year’s challenge was the second I participated in, and the first one I completed. You can find my notes/scripts for all the challenges here. This post presents my solution to the 11th challenge, using the angr symbolic execution library.
The hint for this challenge was “Hey, at least it’s not subleq.” A quick google search shows that SUBLEQ is an example of a “One instruction set computer”, and apparently there was a prior Flare-On challenge with a subleq-based VM. That tips us off that this challenge is also VM-based.
Just looking at string references, it’s clear the function at 140001610 is where the program determines whether our input is correct. Here’s the decompilation of that function in Ghidra after I’ve marked it up:
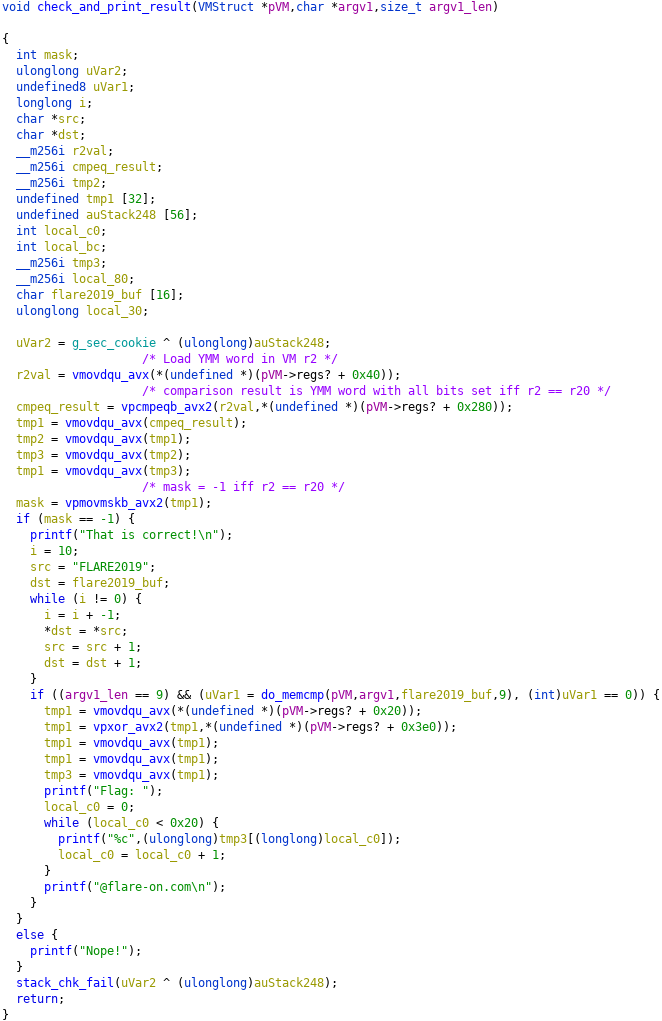
We can see that argv[1] must be equal to “FLARE2019”. Reversing the rest of vv_max.exe, we figure out that the first argument to this function is a pointer to a struct representing the state of a VM. The VM is simple: just an instruction pointer and a set of 256-bit registers, without any instructions to read/write memory. vv_max.exe executes a program with this VM, then checks the result with the function above. Specifically, it will print the flag if r2 == r20 when execution finishes. vv_max.exe takes two command line arguments, which are written into the bytecode before starting the VM.
Each VM instruction is implemented with its own function, and directly corresponds to an AVX/AVX2 instruction. For example, the function at 140003030 implements the instruction with opcode 3. The opcode is followed by a destination register index, and two source register indices (each represented by 1 byte).
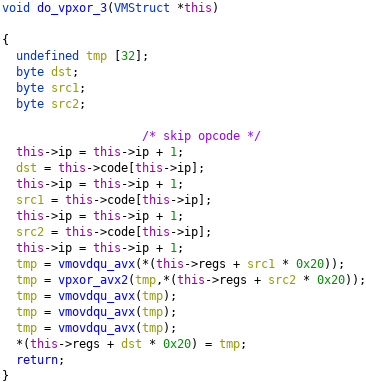
After reversing all the VM instructions, my next step was to implement a disassembler for the VM byte code, which generates this listing:
0: clearregs 1: movimm r0, 0000000000000000000000000000000000000000000000000000000000000000 35: movimm r1, 0000000000000000000000000000000000000000000000000000000000000000 69: movimm r3, 15111111111111111111131a1b1b1b1a15111111111111111111131a1b1b1b1a 103: movimm r4, 1010010204080408101010101010101010100102040804081010101010101010 137: movimm r5, 00101304bfbfb9b9000000000000000000101304bfbfb9b90000000000000000 171: movimm r6, 2f2f2f2f2f2f2f2f2f2f2f2f2f2f2f2f2f2f2f2f2f2f2f2f2f2f2f2f2f2f2f2f 205: movimm r10, 4001400140014001400140014001400140014001400140014001400140014001 239: movimm r11, 0010010000100100001001000010010000100100001001000010010000100100 273: movimm r12, 0201000605040a09080e0d0cffffffff0201000605040a09080e0d0cffffffff 307: movimm r13, 000000000100000002000000040000000500000006000000ffffffffffffffff 341: movimm r16, ffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff 375: movimm r17, 19cde05babd9831f8c68059b7f520e513af54fa572f36e3c85ae67bb67e6096a 409: movimm r18, d55e1caba4823f92f111f1595bc25639a5dbb5e9cffbc0b591443771982f8a42 443: movimm r19, 0400000005000000060000000700000000000000010000000200000003000000 477: movimm r20, 0000000000000000000000000000000000000000000000000000000000000000 511: movimm r21, 0100000001000000010000000100000001000000010000000100000001000000 545: movimm r22, 0200000002000000020000000200000002000000020000000200000002000000 579: movimm r23, 0300000003000000030000000300000003000000030000000300000003000000 613: movimm r24, 0400000004000000040000000400000004000000040000000400000004000000 647: movimm r25, 0500000005000000050000000500000005000000050000000500000005000000 681: movimm r26, 0600000006000000060000000600000006000000060000000600000006000000 715: movimm r27, 0700000007000000070000000700000007000000070000000700000007000000 749: vpermd r20, r0, r20 753: vpermd r21, r0, r21 757: vpermd r22, r0, r22 761: vpermd r23, r0, r23 765: vpermd r24, r0, r24 769: vpermd r25, r0, r25 773: vpermd r26, r0, r26 777: vpermd r27, r0, r27 781: vpsrld r7, r1, 0x4 785: vpxor r28, r20, r21 789: vpxor r28, r28, r22 793: vpxor r28, r28, r23 797: vpxor r28, r28, r24 801: vpxor r28, r28, r25 805: vpxor r28, r28, r26 809: vpxor r28, r28, r27 813: vpand r7, r7, r6 817: vpslld r29, r17, 0x7 821: vpsrld r30, r17, 0x19 825: vpor r15, r29, r30 829: vpcmpeqb r8, r1, r6 833: vpslld r29, r17, 0x15 837: vpsrld r30, r17, 0xb 841: vpor r29, r29, r30 845: vpxor r15, r15, r29 849: vpcmpeqb r8, r1, r6 853: vpslld r29, r17, 0x1a 857: vpsrld r30, r17, 0x6 861: vpor r29, r29, r30 865: vpxor r15, r15, r29 869: vpxor r29, r20, r16 873: vpand r30, r20, r18 877: vpxor r29, r29, r30 881: vpaddd r15, r29, r15 885: vpaddd r20, r15, r0 889: vpaddb r7, r8, r7 893: vpxor r29, r20, r28 897: vpermd r17, r29, r19 901: vpshufb r7, r5, r7 905: vpslld r29, r17, 0x7 909: vpsrld r30, r17, 0x19 913: vpor r15, r29, r30 917: vpslld r29, r17, 0x15 921: vpsrld r30, r17, 0xb 925: vpor r29, r29, r30 929: vpxor r15, r15, r29 933: vpslld r29, r17, 0x1a 937: vpsrld r30, r17, 0x6 941: vpor r29, r29, r30 945: vpxor r15, r15, r29 949: vpaddb r2, r1, r7 953: vpxor r29, r21, r16 957: vpand r30, r21, r18 961: vpxor r29, r29, r30 965: vpaddd r15, r29, r15 969: vpaddd r21, r15, r0 973: vpxor r29, r21, r28 977: vpermd r17, r29, r19 981: vpxor r20, r20, r21 985: vpslld r29, r17, 0x7 989: vpsrld r30, r17, 0x19 993: vpor r15, r29, r30 997: vpslld r29, r17, 0x15 1001: vpsrld r30, r17, 0xb 1005: vpor r29, r29, r30 1009: vpxor r15, r15, r29 1013: vpslld r29, r17, 0x1a 1017: vpsrld r30, r17, 0x6 1021: vpor r29, r29, r30 1025: vpxor r15, r15, r29 1029: vpmaddubsw r7, r2, r10 1033: vpxor r29, r22, r16 1037: vpand r30, r22, r18 1041: vpxor r29, r29, r30 1045: vpaddd r15, r29, r15 1049: vpaddd r22, r15, r0 1053: vpxor r29, r22, r28 1057: vpermd r17, r29, r19 1061: vpxor r20, r20, r22 1065: vpslld r29, r17, 0x7 1069: vpsrld r30, r17, 0x19 1073: vpor r15, r29, r30 1077: vpslld r29, r17, 0x15 1081: vpsrld r30, r17, 0xb 1085: vpor r29, r29, r30 1089: vpxor r15, r15, r29 1093: vpslld r29, r17, 0x1a 1097: vpsrld r30, r17, 0x6 1101: vpor r29, r29, r30 1105: vpxor r15, r15, r29 1109: vpmaddwd r2, r7, r11 1113: vpxor r29, r23, r16 1117: vpand r30, r23, r18 1121: vpxor r29, r29, r30 1125: vpaddd r15, r29, r15 1129: vpaddd r23, r15, r0 1133: vpxor r29, r23, r28 1137: vpermd r17, r29, r19 1141: vpxor r20, r20, r23 1145: vpslld r29, r17, 0x7 1149: vpsrld r30, r17, 0x19 1153: vpor r15, r29, r30 1157: vpslld r29, r17, 0x15 1161: vpsrld r30, r17, 0xb 1165: vpor r29, r29, r30 1169: vpxor r15, r15, r29 1173: vpslld r29, r17, 0x1a 1177: vpsrld r30, r17, 0x6 1181: vpor r29, r29, r30 1185: vpxor r15, r15, r29 1189: vpxor r29, r24, r16 1193: vpand r30, r24, r18 1197: vpxor r29, r29, r30 1201: vpaddd r15, r29, r15 1205: vpaddd r24, r15, r0 1209: vpxor r29, r24, r28 1213: vpermd r17, r29, r19 1217: vpxor r20, r20, r24 1221: vpslld r29, r17, 0x7 1225: vpsrld r30, r17, 0x19 1229: vpor r15, r29, r30 1233: vpslld r29, r17, 0x15 1237: vpsrld r30, r17, 0xb 1241: vpor r29, r29, r30 1245: vpxor r15, r15, r29 1249: vpslld r29, r17, 0x1a 1253: vpsrld r30, r17, 0x6 1257: vpor r29, r29, r30 1261: vpxor r15, r15, r29 1265: vpxor r29, r25, r16 1269: vpand r30, r25, r18 1273: vpxor r29, r29, r30 1277: vpaddd r15, r29, r15 1281: vpaddd r25, r15, r0 1285: vpxor r29, r25, r28 1289: vpermd r17, r29, r19 1293: vpxor r20, r20, r25 1297: vpshufb r2, r2, r12 1301: vpslld r29, r17, 0x7 1305: vpsrld r30, r17, 0x19 1309: vpor r15, r29, r30 1313: vpslld r29, r17, 0x15 1317: vpsrld r30, r17, 0xb 1321: vpor r29, r29, r30 1325: vpxor r15, r15, r29 1329: vpslld r29, r17, 0x1a 1333: vpsrld r30, r17, 0x6 1337: vpor r29, r29, r30 1341: vpxor r15, r15, r29 1345: vpxor r29, r26, r16 1349: vpand r30, r26, r18 1353: vpxor r29, r29, r30 1357: vpaddd r15, r29, r15 1361: vpaddd r26, r15, r0 1365: vpxor r29, r26, r28 1369: vpermd r17, r29, r19 1373: vpxor r20, r20, r26 1377: vpslld r29, r17, 0x7 1381: vpsrld r30, r17, 0x19 1385: vpor r15, r29, r30 1389: vpslld r29, r17, 0x15 1393: vpsrld r30, r17, 0xb 1397: vpor r29, r29, r30 1401: vpxor r15, r15, r29 1405: vpslld r29, r17, 0x1a 1409: vpsrld r30, r17, 0x6 1413: vpor r29, r29, r30 1417: vpxor r15, r15, r29 1421: vpermd r2, r2, r13 1425: vpxor r29, r27, r16 1429: vpand r30, r27, r18 1433: vpxor r29, r29, r30 1437: vpaddd r15, r29, r15 1441: vpaddd r27, r15, r0 1445: vpxor r29, r27, r28 1449: vpermd r17, r29, r19 1453: vpxor r20, r20, r27 1457: movimm r19, ffffffffffffffffffffffffffffffffffffffffffffffff0000000000000000 1491: vpand r20, r20, r19 1495: movimm r31, 221e1b4b2d17050c15590e782326332e10074f731836580b290f5c3a0c627621
The 32 byte immediate values loaded into r0 and r1 in the beginning of the program are replaced by argv[1] (“FLAREON2019”) and argv[2] before the bytecode is executed. Rather than reversing the listing, I decided it would be easier to modify my disassembler to output C code, compile it, then use angr on the resulting binary to solve for the value of argv[2] that makes r2 == r20 when the program exits. Why not use angr directly on vv_max.exe? Because the symbolic execution is massively slowed down by tracing through the VM execution.
The final conversion script is below. I referenced this site to find the intrinsics corresponding to each instruction. Note that at the time of the competition, prior to this commit, angr did not support the vpmaddwd instruction, so I substituted a simple C function for the intrinsic.
#!/usr/bin/env python3
import textwrap
import cle
INSTRS = [
{}, # clearregs, dont bother implementing
{'mnemonic': 'vpmaddubsw', 'args': ['r', 'r'], 'intrinsic': '_mm256_maddubs_epi16'},
{'mnemonic': 'vpmaddwd', 'args': ['r', 'r'], 'intrinsic': 'do_vpmaddwd'},
{'mnemonic': 'vpxor', 'args': ['r', 'r'], 'intrinsic': '_mm256_xor_si256'},
{'mnemonic': 'vpor', 'args': ['r', 'r'], 'intrinsic': '_mm256_or_si256'},
{'mnemonic': 'vpand', 'args': ['r', 'r'], 'intrinsic': '_mm256_and_si256'},
{}, # bitwise_not, unused
{'mnemonic': 'vpaddb', 'args': ['r', 'r'], 'intrinsic': '_mm256_add_epi8'},
{}, # vpsubb, unused
{}, # vpaddw, unused
{}, # vpsubw, unused
{'mnemonic': 'vpaddd', 'args': ['r', 'r'], 'intrinsic': '_mm256_add_epi32'},
{}, # vpsubd, unused
{}, # vpaddq, unused
{}, # vpsubq, unused
{}, # vpmulq, unused
{}, # movreg, unused
{'mnemonic': 'movimm', 'args': ['imm256']},
{'mnemonic': 'vpsrld', 'args': ['r', 'imm8'], 'intrinsic': '_mm256_srli_epi32'},
{'mnemonic': 'vpslld', 'args': ['r', 'imm8'], 'intrinsic': '_mm256_slli_epi32'},
{'mnemonic': 'vpshufb', 'args': ['r', 'r'], 'intrinsic': '_mm256_shuffle_epi8'},
{'mnemonic': 'vpermd', 'args': ['r', 'r'], 'intrinsic': '_mm256_permutevar8x32_epi32'},
{'mnemonic': 'vpcmpeqb', 'args': ['r', 'r'], 'intrinsic': '_mm256_cmpeq_epi8'},
{} # nop, unused
]
TEMPLATE = '''
#include <immintrin.h>
{constants}
{vpmaddwd_implementation}
int main(int argc, char **argv) {{
// Code to initialize variables r0-r31 to zero
{zero_init_regs}
// Converted bytecode
{body}
// Replicate the checks from the function at 140001610 of vv_max.exe
__m256i cmpresult = _mm256_cmpeq_epi8(r2, r20);
int32_t result = _mm256_movemask_epi8(cmpresult);
// We want result == -1
return result;
}}
'''
VPMADDWD_IMPLEMENTATION = '''
__m256i do_vpmaddwd(__m256i a, __m256i b) {
int32_t intermediate[16] = {0};
int32_t result[8] = {0};
for (int i = 0; i < 16; ++i) {
intermediate[i] = ((int16_t*)&a)[i] * ((int16_t*)&b)[i];
}
for (int i = 0; i < 8; ++i) {
result[i] = intermediate[2*i] + intermediate[2*i + 1];
}
return _mm256_loadu_si256((__m256i const *)result);
}
'''
vv_max = cle.Loader('vv_max.exe')
vv_max.memory.seek(0x140015350)
code = vv_max.memory.read(0x5fb)
code = code[1:] # skip the first instruction "clearregs"
constants = []
statements = []
while code and code[0] != 0xff:
opcode, dstreg, code = code[0], code[1], code[2:]
if INSTRS[opcode]['mnemonic'] == 'movimm':
immediate, code = code[:32], code[32:]
immarr = '{' + ', '.join(hex(b) for b in immediate) + '}'
constsym = f'CONST{len(constants)}'
constdecl = f'const char {constsym}[32] = {immarr};'
constants.append(constdecl)
statements.append(f'r{dstreg} = _mm256_loadu_si256((__m256i const *){constsym});')
continue
instrinfo = INSTRS[opcode]
args = []
for argtype in instrinfo['args']:
if argtype == 'r':
rnum, code = code[0], code[1:]
args.append(f'r{rnum}')
elif argtype == 'imm8':
imm, code = code[0], code[1:]
args.append(f'{hex(imm)}')
else:
raise Exception(f'Unrecognized argument type {argtype}')
intrinsic = instrinfo['intrinsic']
arglist = ', '.join(args)
statements.append(f'r{dstreg} = {intrinsic}({arglist});')
src = TEMPLATE.format(
constants='\n'.join(constants),
vpmaddwd_implementation=VPMADDWD_IMPLEMENTATION,
zero_init_regs=textwrap.indent('\n'.join(f'__m256i r{i} = _mm256_setzero_si256();'
for i in range(32)),
' '*4),
body=textwrap.indent('\n'.join(statements), ' '*4))
print(src)This script outputs a C source file. Compile that with gcc -o converted -mavx2 out.c and we can run the following script to leverage angr to solve for the value of argv[2].
#!/usr/bin/env python3
import angr
import claripy
proj = angr.Project('./converted')
main_addr = proj.loader.find_symbol('main').rebased_addr
# Address of initializer for r0 (corresponds to vv_max.exe argv[1])
const0_addr = proj.loader.find_symbol('CONST0').rebased_addr
# Address of initializer for r1 (corresponds to vv_max.exe argv[2])
const1_addr = proj.loader.find_symbol('CONST1').rebased_addr
# Write "FLARE2019" into CONST0
proj.loader.memory.store(const0_addr, b'FLARE2019')
# Find address of ret instruction in main()
cfg = proj.analyses.CFGFast(force_complete_scan=False,
function_starts=[main_addr])
ret_block, = cfg.functions[main_addr].ret_sites
assert ret_block.bytestr[-1] == 0xc3
ret_addr = ret_block.addr + ret_block.size - 1
initial_state = proj.factory.entry_state()
simmgr = proj.factory.simulation_manager(initial_state)
simmgr.explore(find=main_addr).unstash(from_stash='found', to_stash='active')
active, = simmgr.active
arg2 = claripy.BVS('arg2', 0x20 * 8)
active.memory.store(const1_addr, arg2)
simmgr.explore(find=ret_addr)
found, = simmgr.found
found.solver.add(found.regs.eax == -1)
# Restrict solutions to be alphanumeric
for b in arg2.chop(8):
found.solver.add(found.solver.Or(
found.solver.And(b >= ord('A'), b <= ord('Z')),
found.solver.And(b >= ord('a'), b <= ord('z')),
found.solver.And(b >= ord('0'), b <= ord('9'))))
arg2_value = found.solver.eval_one(arg2, cast_to=bytes).decode('utf8')
print(f'arg2 needs to be "{arg2_value}"')Finally, we have what we need to solve the challenge!

Comments